Notes on our internal data pipeline
Overview
To create SCALES data files and furnish data to SCALES apps, we scrape court data from publicly available sources and apply a series of transformations to those data before making them available at public endpoints. In its most abstract form, this data pipeline is structured as follows:
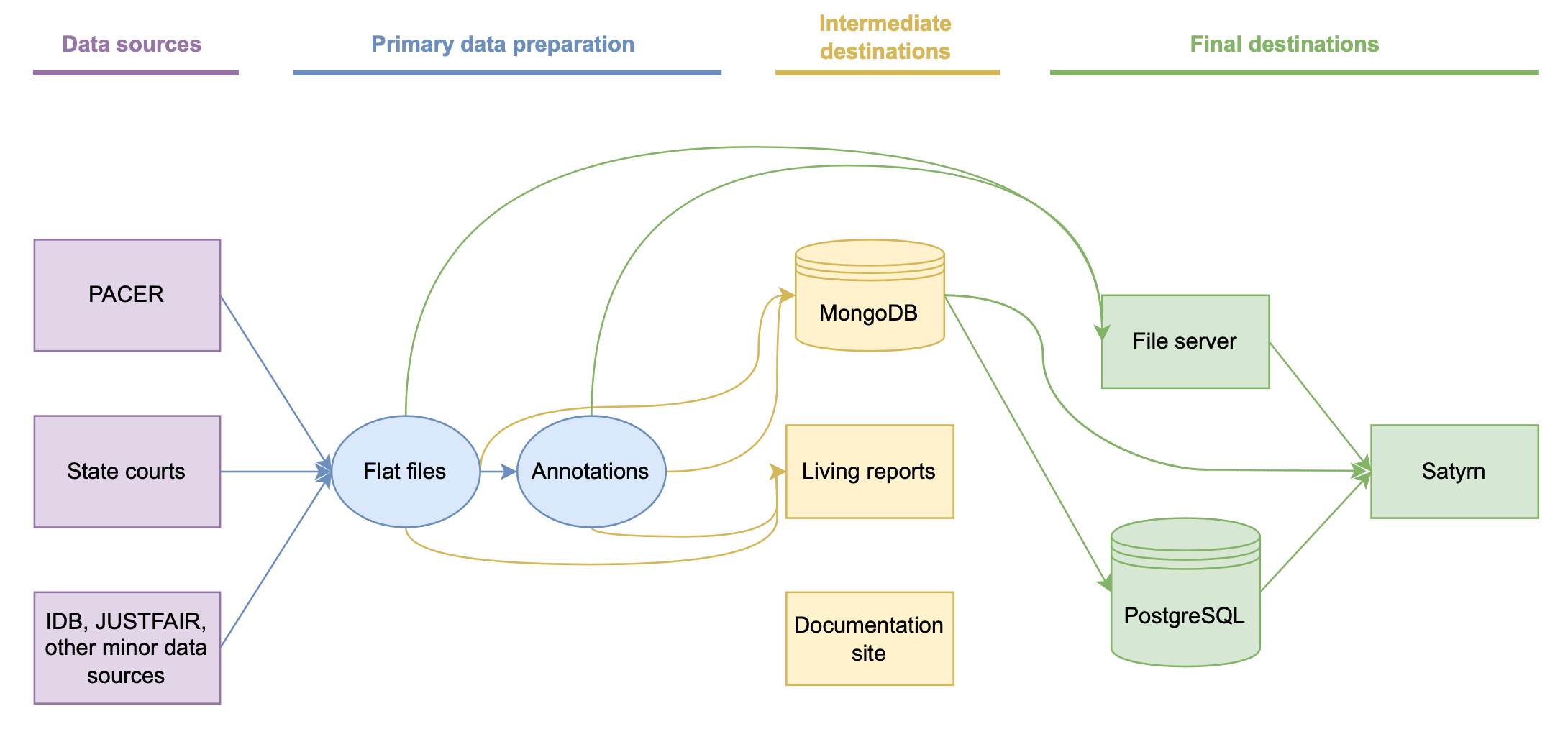
Elsewhere on this website, we describe various SCALES products: aggregate data files, public versions of the inference algorithms contributing to those files, and software tools we developed while working on those files. This document, however, describes the underlying data-manipulation process that produced those files. It's both a guide for users curious about SCALES's behind-the-scenes data practices and a reference for SCALES developers themselves.
General development & maintenance needed
- All data from the state courts of Clayton County are currently confined to the "primary data preparation" layer, and major changes to the subsequent layers will be needed in order for the Clayton data to flow onwards. Additionally, we are in the process of expanding our data holdings to state courts beyond Clayton, and given that the courts at this level vary greatly in their record-keeping practices, many of the components below may need to be modified to accommodate the shapes of the new data.
- At present, we're sending data through the pipeline in large, infrequent batches. If a time ever comes when we need to execute some or all of the pipeline with more regularity, many of the components below may need to be modified to be more easily triggerable through Airflow (which we've used in the past, mianly for scraping runs) or some other workflow-management solution.
- Some of the components below are tied to Northwestern University (SCALES's former home) and may need to be relocated if NU changes SCALES's access rights; specifically, Delilah is a physical server located on NU's Evanston campus (and therefore behind the NUIT firewall, meaning an NU NetID is required for SSH access), and our file server is a machine administered by NUIT. Fortunately, SCALES has full control over the rest of the pipeline, via DigitalOcean (Mongo, Postgres, living reports, Satyrn), GitHub Pages (documentation site), and WordPress DNS records (the
livingreports,docs,satyrn, andsatyrn-qasubdomains of scales-okn.org).
Data sources
Everything that flows through our pipeline originates from just a handful of locations:
Federal courts (PACER)
Detailed and uniform across 94 U.S. federal district courts, PACER case records are a vital tool for legal scholars. In our early days, SCALES focused exclusively on PACER, buying paywalled cases and making them freely available in an easy-to-use format. Even as our interests and technical capabilities have expanded, PACER data has remained a fruitful target for research and thus a continuing focus. (Pending either new partnerships & funding or a revived "Free PACER" bill, we hope to scrape even more PACER data in the future.)
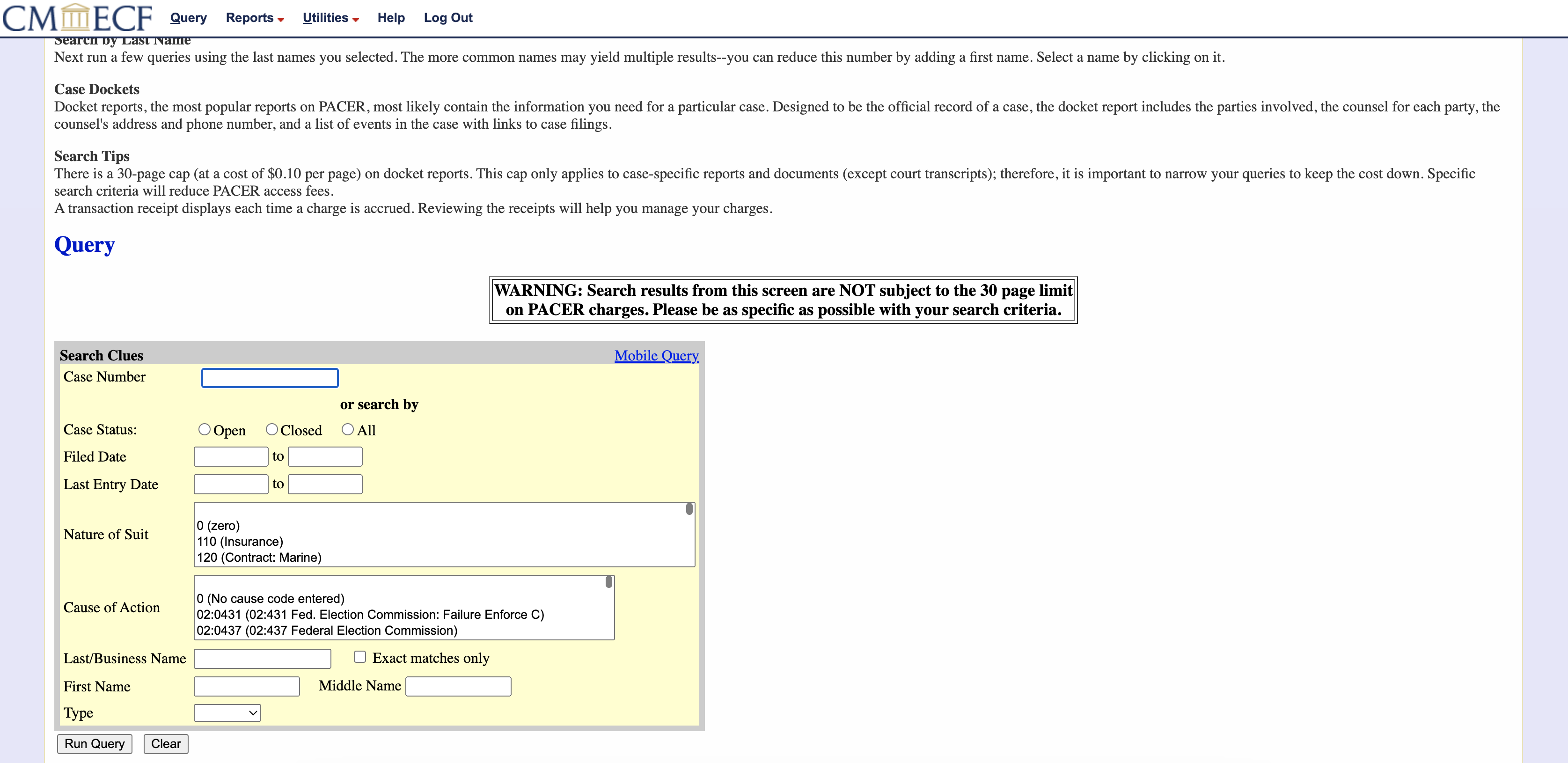
Out of the 1,278,268 total PACER cases in our dataset, we scraped 1,181,616¹ cases ourselves, during the following intervals ("cross-sectional" refers to data across all courts):
- 1/1/19-1/10/19 (and a few on 7/29/21): longitudinal data in N.D. Ga (2010 & 2015; 11,398 cases)
- 12/9/18–10/25/23, multiple runs²: longitudinal data in N.D. Ill (2002 – Mar '21; 199,664 cases)
- 11/14/17–10/25/23, mostly Jan-Feb '20: cross-sectional data for '16, non-N.D.-Ill (247,416 cases)
- 1/31/20–10/25/23, mostly Jul '21: cross-sectional data for '17, non-N.D.-Ill (319,718 cases)
- 6/22/21–5/3/23: misc data in 14 courts³ (new filings; 4694 cases; initial docket entries only)
- 2/8/22–3/14/22: longitudinal data in E.D. Pa (2002-21; 326,102 cases; private use only)
- 8/2/22–8/26/22: longitudinal data in TX (2018 & 2020; 72,349 cases)
The remaining 96,652 cases are those we've received via data dumps of PACER HTMLs from third parties, which were originally scraped by those third parties during the following intervals:
- 11/14/17–8/19/21, mostly Jun '19: misc data for '16 (86,169 cases; Free Law Project)
- 1/10/23–1/21/23: misc data in AL, GA, & IL (10,483 cases; Civil Rights Litigation Clearinghouse)
Finally, as a part of various projects, we've revisited some cases we already scraped in order to pull any new docket entries that may have appeared since our first download. The resulting HTML files — which the scraper code refers to as "case updates" — are fragmentary, in that their docket tables have been run through PACER's date filter and contain only the new entries (although the HTML fragments are re-unified into single JSON files later on, during the parsing step of the pipeline). To distinguish case-update files from the original files, the scraper uses the name 12345_1.html for the first update to case 12345.html, and the index after the underscore increases for subsequent updates. We've downloaded 19,492 case-update files, but because the cases in these files are already represented elsewhere in the corpus, they are not included in the case totals above.
The specific cases downloaded during the above runs are listed in the "case lists" folder hosted on our file server; more information on those case lists can be found here.
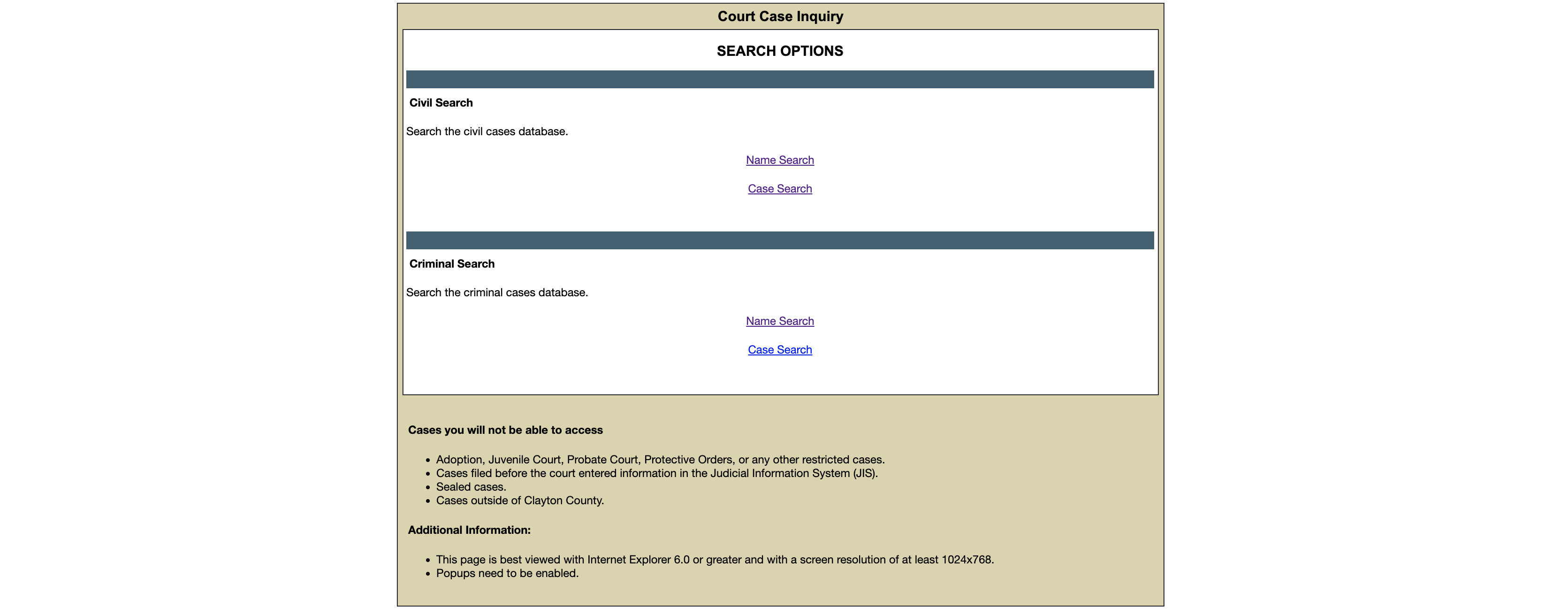
State courts
The sprawling, unstandardized, and inconsistently documented state courts pose myriad challenges to researchers, but given that most U.S. legal activity occurs on the state level, cases in these courts are a crucial piece of the legal-research puzzle. As of this writing, our state-court scraping work is in its pilot phase in the courts of Clayton County, GA, in partnership with the American Equity & Justice Group and supported by Georgia State University's Project RISE. In the coming year, we also plan to begin scraping data from courts in other counties.
We've scraped a total of 3,207,790 Clayton County cases during the following intervals ("n>100" refers to the first year with more than 100 cases):
- 10/24/22–11/11/22: all criminal data in superior court (108,546 cases; from 1973; n>100 fr 1984)
- 11/22/22–1/14/23: all criminal data in magistrate court (538,845 cases; from 1985; n>100 fr 1994)
- 1/18/23–3/28/23: all criminal data in state court (1,483,795 cases; from 1967; n>100 from 1981)
- 10/3/23–11/7/23: all civil data in superior court (112,245 cases; from 1968; n>100 from 1989)
- 11/8/23–1/3/24: all civil data in magistrate court (771,957 cases; from 1987; n>100 from 1991)
- 3/25/24-4/7/24: all civil data in state court (192,402 cases; from 1982; n>100 from 1989)
Minor data sources
The following data sources don't play a major role in our data work, but they're nevertheless passed along the pipeline in one form or another.
FJC IDB
The Federal Judicial Center's Integrated Data Base is one of the only free, comprehensive sources of aggregate data about federal court cases, so it is a common starting point for all manner of research into the U.S. judiciary. However, the FJC's data collection and maintenance processes are somewhat opaque, and systematic gaps and errors in IDB data often plague legal scholars' attempts to use it for large-scale research work; therefore, we include the IDB in our Mongo loads and TTL files not as a valued data source but more so as a point of comparison for researchers accustomed to relying on that dataset.
JUSTFAIR
Created as part of a 2020 study entitled "JUSTFAIR: Judicial System Transparency through Federal Archive Inferred Records" (Ciocanel et al.), the JUSTFAIR dataset is an interesting, if imperfect, attempt at crosswalking PACER data with data from the U.S. Sentencing Commission in order to understand individual judges' sentencing decisions. We include it in our Mongo loads mainly as a courtesy for researchers curious about this ongoing area of research.
Primary data preparation
Flat files
What are they?
When we acquire legal data, we deposit those data in their raw form into files on a secure machine accessible only by SCALES developers (hereafter nicknamed Delilah), on a dedicated volume located at /mnt/datastore. Each file on this volume (excluding the annotations subdirectory) is either (1) a direct transcription of some data pulled from one of the above sources, like an HTML page from PACER, or (2) a parsed version of one of these direct transcriptions, like a JSON version of an HTML file. (Though it may seem odd to describe both these methods of flat-file production as "depositing data in their raw form," all of our parsing code has been designed to write JSONs that are as "raw" as possible — that is, to provide near-lossless translation from one format to another, where "loss" excludes loss of contextually meaningless information such as, say, inline CSS.)
This collection of flat files is the ground truth upon which all further SCALES work is based; in other words, the flat files comprise our data lake, or the lowest layer of our data stack. The files are "flat" in that they stand alone; they exist in a relatively unstructured state and aren't linked together in a database or other such imposed structure.
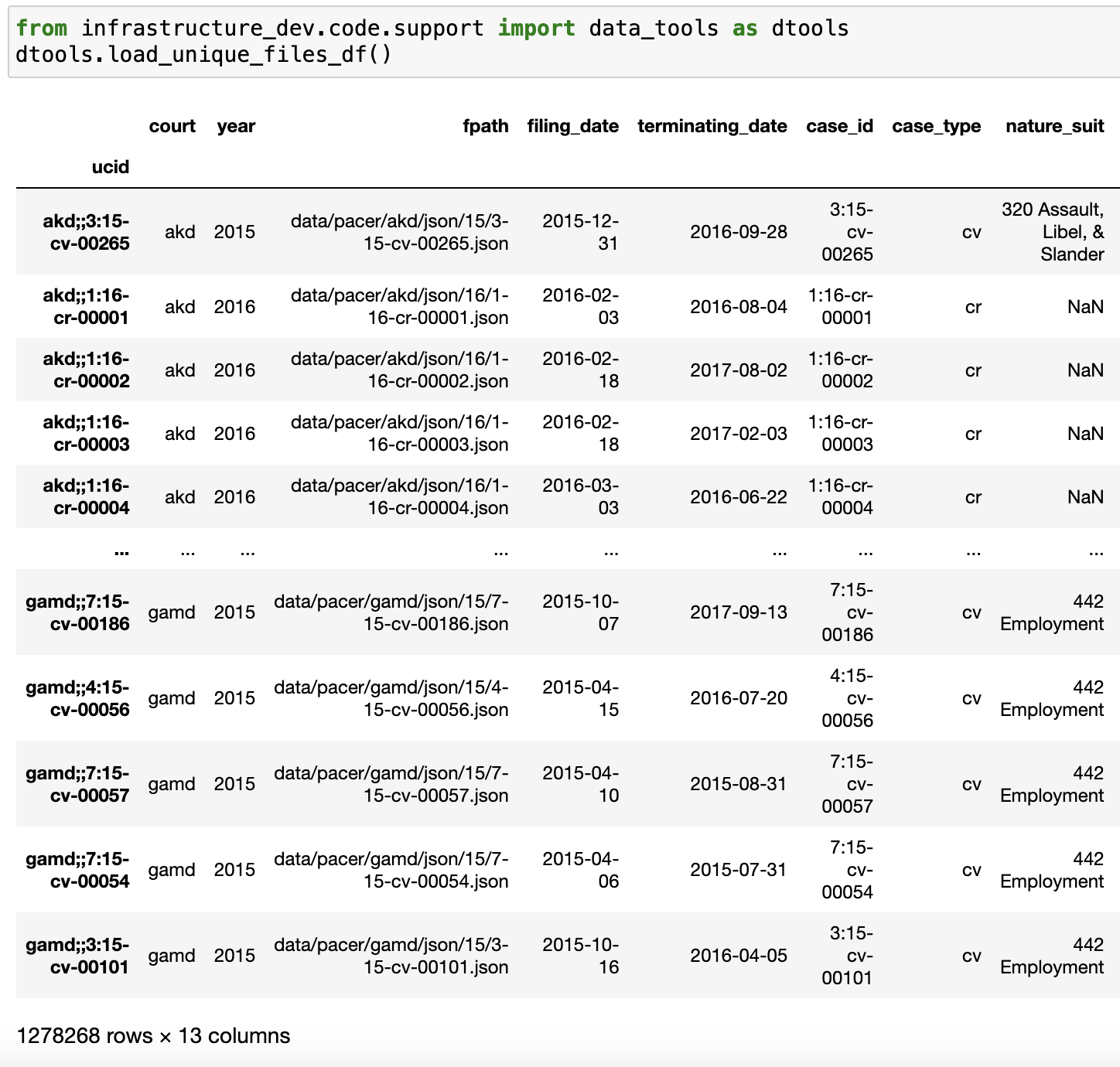
The flat files are designed primarily as raw material to be passed further along the pipeline, but they can also be useful in their own right. For users outside the SCALES organization, this guide suggests some use cases for our PACER JSONs. And for our internal work, we've further augmented the flat files' utility via a PACER metadata table at /mnt/datastore/unique_docket_filepaths_table.csv on Delilah, which facilitates direct file reads and simple aggregation (as well as providing a full list of PACER filepaths at a few points in the pipeline, like in the make_ucid_lists.py script used to populate the file server). The following wrapper function provides straightforward access to the table:
How are they produced?
We acquire the data in /mnt/datastore by running scraping scripts that capture web pages as HTML files, and subsequently running parsing scripts that convert the HTMLs to cleaner, more structured JSON files. Our scraping libraries reside in infrastructure_dev/code/downloader (PACER) & downloader_county (state courts), and our parsing libraries can be found in infrastructure_dev/code/parsers (PACER) & parsers_county (state courts). The documentation pages for the PACER scraper and parser contain more information about these libraries; additionally, the directory infrastructure_dev/code/parsers/schemas contains files describing the structure of our PACER JSONs using JSON Schema syntax. (Public versions of the PACER scraping/parsing scripts are available in the PACER-tools repo, maintained via infrastructure/code/sync_public.py, and the pacer-tools pypi package, maintained via the instructions in PACER-tools/setup.py.)
We use the workflow-management platform Airflow to schedule our scraping runs outside of working hours (in order to avoid overtaxing court servers) and to facilitate any runs large enough that they need to be spread across multiple days. Airflow jobs execute in a Docker container on Delilah, from which they communicate via ssh with a separate container dedicated to running infrastructure_dev scripts. The code for this system, as well as a readme with more information, can be found in infrastructure_dev/code/apps/conductor.
As for the minor data sources in our datastore, we used the scripts at infrastructure_dev/code/tasks/fjc_*.py for all data munging related to the FJC IDB, and we used the notebook at infrastructure_dev/code/experiments/justfair/playground.ipynb to produce the one JUSTFAIR file not taken right from the study (/mnt/datastore/justfair/ucid_dataset.csv). Finally, to maintain the PACER metadata table, we use the scripts build_unique_table.py and update_uft.py in infrastructure_dev/code/tasks.
Development & maintenance needed
- The unique files table currently tracks only PACER data; eventually, we'll want to extend the table to state-court data (and perhaps even to the minor data sources).
- On various occasions, we've experimented with downloading some of the documents that are linked from specific PACER docket lines, which are usually PDF copies of individual filings by litigants; we've stored these documents parallel to the HTML & JSON files in
/mnt/datastore/paceron Delilah. At present, we're not doing anything with the PDFs, but eventually we'd like to pass them further along in the pipeline, either via simple database storage (e.g. Mongo GridFS) or more sophisticated OCR work. - No schema files currently exist describing the ways in which the structure of the state court JSON files diverge from the structure of the PACER JSONs (see e.g. the new fields in the Clayton parser marked with the comment "NEW FIELD"). Additionally, since the last update to the PACER schema files, revisions to the PACER parser may have resulted in some small changes to the structure of the PACER JSONs.
Annotations
What are they?
We use the umbrella term "annotation" to refer to a piece of data produced by some kind of inference about the flat files. For PACER cases, we've produced the following categories of annotations, all stored in /mnt/datastore/:
- Judges:
judge_disambiguation/ - Parties:
party_disambiguation/ - Lawyers:
counsel_disambiguation/ - Law firms:
firm_disambiguation/ - Docket-entry tags using SCALES's case-event ontology:
ontology/mongo/labels.csv - Docket-entry tags for in forma pauperis (IFP) activity: currently stored only on Mongo
For Clayton County cases, we've produced the following annotations (albeit most only for a small selection of courts and years), all stored in /mnt/datastore/annotation/counties/ga_clayton/:
- Lawyers:
lawyers.csv,lawyer_appearances_16_to_18.csv - Prison sentences:
superior_sentences.csv - Bond events:
bonds_16_to_18.csv - ROTA/BJS charge categories:
clayton_charge_categories_rota_bjs.csv - Crosswalk from cases in criminal magistrate court to other criminal cases: TBD (in progress)
Other pages on this site contain more information about the entity-disambiguation annotations and ontology annotations.
How are they produced?
For most of the PACER annotations, the PACER case data in the Delilah datastore is the only input. The ontology annotations are the sole exception to this rule; in addition to case data, they depend on model weights from models trained on hand-tagged docket entries. (A SCALES Label Studio instance was the arena in which this hand-tagging took place.)
- Judges:
research_dev/code/research/entity_resolution/judges_private/JED_*.py(excludingJED_Xhelper scripts) - Lawyers:
research_dev/code/research/entity_resolution/run_counsel_pipeline.py - Law firms:
research_dev/code/research/entity_resolution/run_firm_pipeline.py - Ontology tags: scales-nlp pypi package (see also the SCALES NLP documentation)
- IFP tags:
research_dev/code/research/ifp/build_judge_ifp_data.py
(Note that changes to the scales-nlp package can be published to pypi using the same method described in PACER-tools/setup.py.)
We've generated most of the Clayton County annotations on an as-needed basis, using code not yet published to any of our repos. An exception is superior_sentences.csv, which comes from research_dev/code/research/counties/ga_clayton/parse_sentences.py.
Development & maintenance needed
- The party-disambiguation pipeline should be fully implemented in parallel with the counsel/firm disambiguation pipelines, as outlined in the documentation for the latter pipelines.
- The ad-hoc Jupyter notebook operations which were used to generate the Clayton County annotations should be moved into scripts.
- An IFP-annotations file should be added to the datastore.
Intermediate destinations
MongoDB database
How is it produced?
Each load to Mongo begins with the name of a Mongo collection being passed to infrastructure_dev/code/db/mongo/update_collection.py. This script takes care of some high-level tasks like incrementing version numbers before calling mongo_tools.py, which ingests data from either the flat files or the annotations and then performs the actual load. (Note that any loads to the cases_html collection will now require a costly rewrite of the full-text search index in that collection, as explained in the section on Satyrn.)
What is it?
Our Mongo database, hosted on DigitalOcean, is a data-sharing solution for anyone who needs simple table-style access to our data, and/or anyone who doesn't want to go the trouble of downloading and storing the flat-file versions of the data (or who needs only a small subset of the files included in those gzips).
In the early days of SCALES, this Mongo instance was our only means of disseminating data. Later, when we took over development of the Satyrn app, we also inherited the Postgres database that the original developers had been using to supply PACER data to the app, which prompted us to consider retiring the Mongo database and using Postgres for all our data-distribution needs. However, we felt it was important to have somewhere to host any data not usable in Satyrn but still useful in other contexts, like the civil-rights stub cases we scraped for NACDL. Accordingly, we've limited Postgres to its original role as a data source for Satyrn, while we use Mongo for everything else.
To obviate the need to look up the syntax associated with pymongo.MongoClient, we provide a wrapper class called SCALESMongo in support/mongo_connector.py that can be called as follows (by users with Mongo credentials):
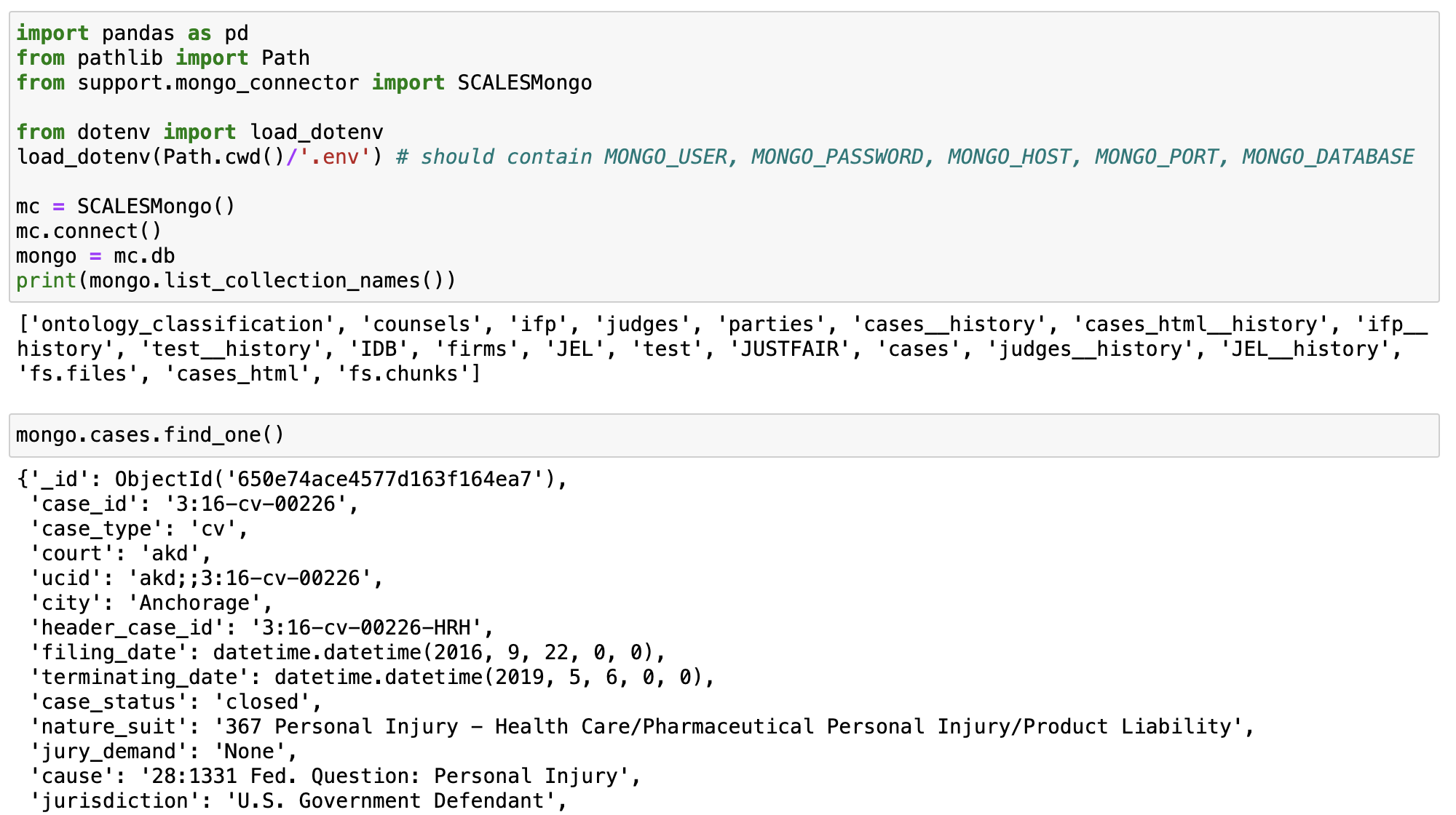
More information on both the load process and characteristics of the database itself can be found in the readme.
Development & maintenance needed
- The Mongo readme is incomplete and slightly out of date (e.g. it dates back to a time when we hoped to use Airflow to automate most of this pipeline).
- During the load to Mongo, we remove social security numbers and prisoner numbers from the case data, using a call written into the loading code to the regex-based
data_tools.remove_sensitive_info(). The SSN-removal part of this function is fairly robust, but the detection of prisoner numbers is a bit spotty and could be improved. - The Mongo-load step of the pipeline is also the point at which we redact the names of private individuals from the case data. Our current strategy is to run the redaction code on the full PACER dataset (via
tasks/redact_pacer.py) to create apacer_redacteddirectory, which we then load to Mongo in bulk. This strategy works fine, but if we begin doing Mongo loads on a more piecemeal basis (or if we want to ensure that no one accidentally skips the redaction step when loading to Mongo), then it may be preferable to call the redaction code directly from the loading code, as with the SSN removal.
Living reports
How are they produced?
The living-reports app consists of a Vue frontend and Flask backend, running on a droplet at livingreports.scales-okn.org; the project directory on that droplet is /var/www/html/living_reports. For info on maintaining the current infrastructure and adding new reports, see the readme for the living_reports repo, as well as this more explicit tutorial.
Specialized data files provide the data used by the reports. We generate these files on Delilah and scp them to living_reports/flask/data on the droplet, as follows:
- In forma pauperis (IFP): PACER cases & judge annotations -->
research_dev/code/research/ifp/build_judge_ifp_data.py-->data/all_districts_ifpcases_clean.csv,data/judge_var_sig.csv,data/judge_var_sig_lookup.csv - Sealing: PACER cases --> both scripts in
research_dev/code/research/sealing-->data/items_over_motions.csv⁴ - IDB: PACER cases & IDB -->
research_dev/code/research/idb/living_report_idb.ipynb-->data/idb/idb_overall.csv,data/idb/idb_ifp_false_pos.csv,data/idb/idb_ifp_false_neg.csv - Data coverage: PACER cases --> both notebooks in
research_dev/code/research/data_coverage-->state_coverage.csv,district_coverage.csv,courts_geojson.json
Finally, the app's authentication system relies on a basic SQLite user database, which lives on the droplet at living_reports/flask/db/app.db. We manually edit this database using the methods described in the living_reports readme (if using flask shell, make sure to run conda activate flask-lr first).
What are they?
The living reports are dashboard-style writeups on various topics that we feel may be interesting to our user base. Originally, these reports were an important way for us to highlight SCALES's data-analysis capabilities; when we inherited the Satyrn app, though, we began to spend much less time maintaining and building out the reports.
The living reports on sealing, data coverage, and the IDB are publicly accessible, while the IFP reports are only accessible to users we've added to the small SQLite user database. (There are 94 IFP reports, one for each federal court district, and each user has access to some subset of those reports.)
Development & maintenance needed
- For consistency and ease of maintenance, the current authentication system should be swapped out for the Satyrn authentication endpoint; for further explanation, see the section on the file server, which currently uses that endpoint for authentication.
- Before doing any major work on the living reports, it's worth considering the possibility that, as the Satyrn app improves, it may render future and/or present reports obsolete (or perhaps simply more trouble than they're worth, given the whole separate infrastructure on which they're built).
Documentation site
How is it produced?
The documentation site (or docsite for short) is a simple Vuepress site, served by GitHub Pages at docs.scales-okn.org (which redirects to scales-okn.github.io). Updates to the docsite happen via the docsite/deploy.sh script, as documented in the readme for the docsite repo.
The site content is mostly free-floating prose that isn't procedurally generated in any way, similar to the README.md files you might expect to see in git repositories; in other words, the onus is on SCALES developers to augment and update the docsite as SCALES projects evolve. One exception to this rule is the set of readmes that are copied directly from their respective SCALES repos via docsite/sync_readme.py. At present, this set includes just the PACER scraper and parser, but more readmes can be added to the set by editing the pairs tuple in the script.
What is it?
If the scales-okn GitHub page is the central location where a technically-minded person would go to understand how SCALES products work, the docsite is the equivalent place for a non-technically-minded person. There is some overlap between the two (e.g. the synced readmes mentioned above), but the docsite diverges from the repo readmes in that it hosts some article-like "guides" describing broad swaths of our work, offers some readmes for products that don't have a dedicated repo (e.g. the data files served by the file server), and excludes some readmes unlikely to be of interest to lay users (e.g. the readmes for the Satryn-related repos).
Final destinations
File server
How is it produced?
The file server is a Northwestern-administered machine running at scalesokndata.ci.northwestern.edu. To copy files to the server (which is only possible via SSH from Delilah, due to the NU firewall), we run infrastructure_dev/code/db/rdf/make_ucid_lists.py to determine the cases that should be included and then run make_and_scp_filedumps.sh on the resulting case lists. To make these files available to the outside world, we use the server to host a web app that is modeled after the living-reports app and, as such, consists of a Vue frontend & Flask backend; this app is accessible by anyone with Satyrn credentials.
What is it?
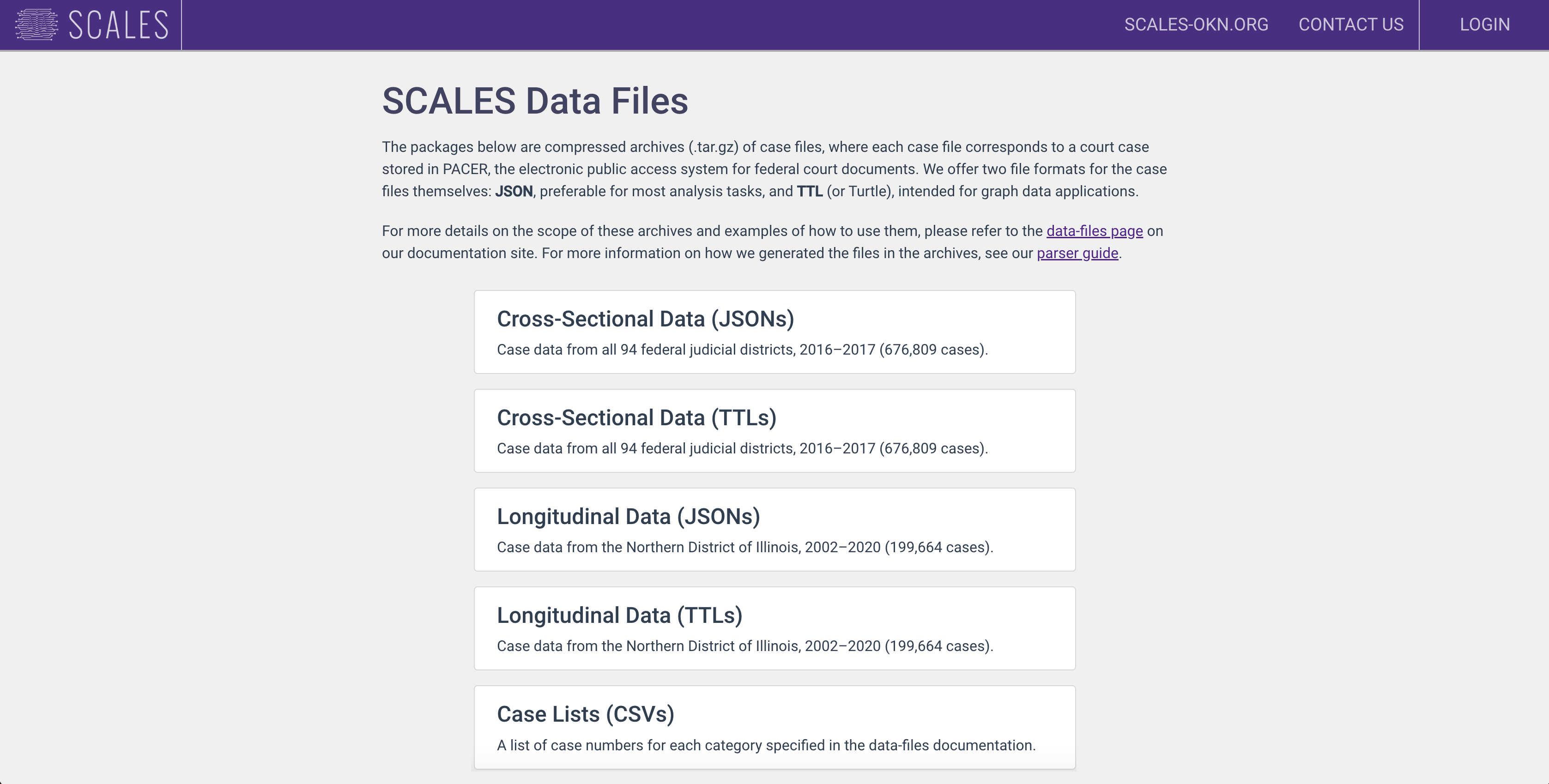
The file server is a data-sharing solution for anyone who prefers to work with copies of the flat JSON files living on our system rather than querying a database, such as users who need fast or streaming access to large volumes of our data and don't mind writing custom code in the process. For various reasons — e.g. the scope of researchers' typical data needs, and our own desire not to update the gzips every time we acquire new data — the two kinds of file collections on the server (longitudinal and cross-sectional) represent a limited, albeit extensive, portion of our total data holdings.
In addition to JSON file dumps, the file server also hosts files in TTL format (Terse RDF Triple Language), which is intended for graph-database use cases. Our inclusion of TTL files was motivated by the overarching priorities of the NSF's Convergence Accelerator program, which has provided the majority of SCALES's funding since our inception. Initially, the TTL files were a proof of concept, demonstrating that court data could be incorporated into the NSF's vision of an "open knowledge network."
At time of writing, however, the TTLs have recently found a practical application. An infrastructure-focused Convergence Accelerator team is building an API endpoint that will allow all other teams to execute SPARQL queries against a graph database, and we plan on granting file-server access to this infrastructure team so they can incorporate the TTL file dumps into their database. Our long-term goal is to translate Satyrn's under-the-hood SQL queries to SPARQL, allowing Satyrn users to interact with the entirety of the NSF's cross-disciplinary graph database; if these efforts are successful, the importance of the file server and its contents will increase significantly.
Finally, the file server hosts a folder containing lists of case numbers, which enumerate the cases in the above file collections as well as several other categories (e.g. the scraper runs described earlier). A full outline of these case lists can be found here.
The data-files documentation page contains more information on both the JSONs and TTLs, as well as usage examples.
Development & maintenance needed
- The case lists are currently maintained manually; if PACER downloads ever pick up speed again, it may be useful to automate the generation of those lists.
PostgreSQL database
What is it?
Our DigitalOcean-hosted Postgres instance is essentially a staging area for data used in the Satyrn app. The original Satyrn development team, when deciding how to deliver data to Satyrn, designed a Postgres schema that they felt would be maximally interoperable with the app. We've adopted this schema with very few changes; despite the overhead of translating from our Mongo schema to this slightly different one, we've found that we can avoid even greater overhead by focusing on reducing friction between Satyrn's data source and the Satyrn app itself. (For an explanation of why we maintain two separate databases in the first place, see the section on Mongo.)
Users with credentials can access the Postgres database as follows:
How is it produced?
To populate the Postgres database, we pass data from Mongo through the ETL sequence in infrastructure_dev/code/db/postgres/scales_mongo_etl.py (which we typically wrap with ucid_mapper.py). For efficiency, we perform a separate bulk load of the ontology annotations, first pulling them from Mongo and staging them in JSONL files in the datastore using scales_ontology_jsonl_writer.py and then loading those files using scales_ontology_jsonl_loader.py.
Development & maintenance needed
- The following columns in the Postgres
casestable, which were originally added via ad-hoc Jupyter-notebook operations to facilitate certain Satyrn analyses on a tight deadline, need to be written into the main Postgres loader:year,court,state,circuit,sjid,nature_suit,ontology_labels,ifp_decision,pacer_pro_se. Additionally, the entire Postgresjudgestable was loaded in this way and needs to be incorporated into the loading code as well. - The Postgres ETL scripts depend on a legacy custom ORM called JumboDB, written many years ago by the C3 Lab. To avoid code bloat and improve maintainability (e.g. by obviating the need for edits in the JumboDB directory in tandem with any changes to the Postgres schema), it may be worth dispensing with JumboDB if a major refactor of the ETL scripts ever occurs. (The original JumboDB repo is no longer publicly available, but we maintain a SCALES fork of the repo at
infrastructure_dev/code/db/postgres/jumbodb.)
Satyrn app
(n.b.: At time of writing, the Satyrn team is considering overhauling the app's data-ingestion functionality by substituting the aforementioned SPARQL endpoint in place of our in-house Postgres endpoint. We plan on keeping this section as up-to-date as possible, but just in case, we suggest you check the satyrn-api repo to see if SPARQL compatibility has been added, e.g. by consulting the db_type switch blocks in the SQL-functions code). If SPARQL has been added, this section may be out of date.)
How is it produced?
The Satyrn app consists of a React/Typescript frontend assisted by a small Postgres database for user data (both derived from the scales-ux repo) and a Flask backend (from the satyrn-api repo), all running on a DigitalOcean droplet at satyrn.scales-okn.org. To load data, the app uses a config file called a "ring," which must contain a database connection string (this is where we pass the IP of our Postgres instance) in addition to a JSON description of the tables in the database and the joins & other operations that can be performed on those tables. Changes to the data in the Postgres database propagate automatically into the app, but whenever there are changes to the structure of the database, the Satyrn dev team must manually update the ring file to reflect those changes.
In theory, Satyrn is a data-agnostic "dumb" platform, meaning that it relies entirely on the ring file when performing analysis and makes no assumptions about the nature of the underlying data. In practice, though, this agnosticism is hard to enforce fully; thus, the app's ability to manipulate SCALES data depends on a few specifically tailored sections of code:
views.py/viewHelpers.py(backend): hardcoded function that preps PACER case HTMLs for frontend viewingextractors.py/seekers.py/views.py/viewHelpers.py(backend): hardcoded table joins during Postgres searches (courts, natures of suit, full-text-search-optimized HTMLs)autocomplete.py(backend),Filter.tsx/LocalAutocomplete.tsx/autocompleteOptions.tsx(frontend): autocomplete optimizations based on specific Postgres fieldsqueryBuilder.ts(frontend): minor hardcoded fixes for requests being sent to the backendBarChartDisplay.tsx/LineChartDisplay.tsx/MultilineChartDisplay.tsx(frontend): minor hardcoded graph fixes
Finally, as a speed optimization to facilitate text searches over case HTMLs, Postgres consults a full-text index on the Mongo cases_html table (via a connection string in the MONGO_URI environment variable) when filtering Postgres-derived case lists during those searches; accordingly, for completeness, an edge pointing directly from Mongo to Satyrn has been included in the flowchart at the top of this guide. It's worth noting that the chances of unexpected behavior⁵ stemming from divergence between Mongo & Postgres are slim to none, given that (1) case-HTML changes/deletions are unlikely ever to occur and (2) any such changes would require the Mongo full-text index to be re-created, a lengthy operation that could only conceivably occur in the context of a full-pipeline update.
What is it?
The Satyrn app is a publicly accessible, no-code, ORM-like research tool styled like a Jupyter notebook. Its main offerings are a variety of filtering, searching, analysis, and plotting operations on PACER data. Kris Hammond's C3 Lab developed the initial versions of Satyrn in order to explore strategies for translating natural-language questions into SQL-style queries against arbitrary databases. When the C3 Lab handed off development duties to SCALES at the end of 2022, we adapted it into a PACER-data-exploration app more closely tailored to our organization's goal of making court data accessible to researchers and the lay public.
More information about the Satyrn codebase can be found in the two repos linked above. As for questions about how to use the Satyrn app itself, we are in the process of implementing in-app tooltips to clarify Satyrn's features and capabilities. In the meantime, feel free to email us or contact the author on GitHub.