Entity Disambiguation
There are multiple entity types (judges, lawyers, law firms, and parties) that need to be disambiguated and resolved across cases, courts, and time in order to answer questions and develop analyses. While the process of disambiguation is fundamentally the same for all entities in our codebase, there are differences in the amount and types of supporting information that can be used to disambiguate two similar names in two cases as a single entity. This results in slightly different pipelines for judges, lawyers and law firms, and parties.
General Disambiguation Pipeline
We leverage assumptions about the structure of the courts to help make stronger inferences of identity between names; specifically, it is far more likely for a lawyer with the name "John Doeremi" to be the same entity as lawyer "John Doeremi" in the same case if both of those cases are in the same court/local geography. Accordingly, all of our pipelines follow roughly the same disambiguation process:
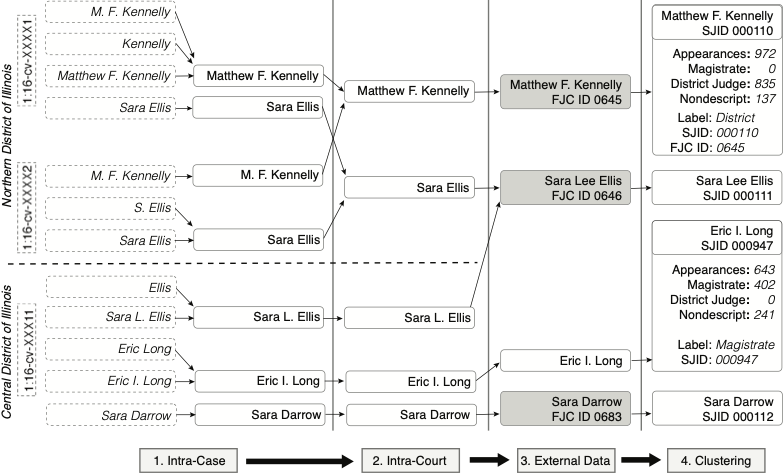
- Intra-case - within each case, either structured fields or named entity recognition models are used to identify the potential entity names that need to be disambiguated.
- Intra-court - potential entity names across cases are clustered based on similarity.
- External Data - data that is external to the court data is introduced to the pipeline, and clusters are created between the external dataset and across court jurisdictions based on similarity. For judges this would be the biographical data, for companies the SEC Edgar CIK information is used, and so on.
- Clustering - final steps are taken to identify possible matches between entity clusters.
Specific Disambiguation Pipelines
Judges
The disambiguation pipeline for judges is currently available in the research materials repository and is described in the IEEE paper describing the PRESIDE model.
Matching Procedures and Assumptions
Matching is based on name similarity and exploits information about the type of honorifics that are used to describe the judge in order to infer their position (district, magistrate, bankruptcy, etc.). Information from the Federal Judicial Center's Biographical Directory is also used to help identify when a judge started to serve as a district judge as opposed to some other capacity.
Judicial positions that we infer based on the docket context:
- District Judge
- Article III Judge
- Appellate Judge
- Supreme Court Justice
- Bankruptcy Judge
- Nondescript Judge - Mention with a generic honorific (Honorable or Judge) that lacks sufficient context to categorize as one of the previous categories.
Categorical labels that we assign to text mentions of a judge when evidence is insufficient to make an identification:
- Ambiguous - there are multiple potential matches to individuals with the same last name and it is ambiguous as to which actual judge took an action (i.e., the mention of Judge Johnson could be Judge Jane Johnson or Judge Joe Johnson and there is insufficient context to resolve who it is).
- Judicial Actor - actors who are not judges but take on administrative roles, such as mediators.
- Inconclusive - unclear who the judge is, likely an issue with named entity recognition from the text entry or how the text itself was entered (severely misspelled name, initials only, concatenation of a name with another word, etc).
External Datasets Used
Lawyers
The disambiguation pipeline code for lawyers will be made publicly available at a date TBD.
Matching Procedures and Assumptions
Matching is based on name similarity, e-mail address, firm name, physical address, and phone number. If no additional fields outside of the name match between two potential entities then we do not create a match between the two names. Since the universe of lawyers is significantly larger than that of judges, we allow for the possiblity that there are lawyers with the exact same name who are different people.
External Datasets Used
None
Law Firms
The disambiguation pipeline code for law firms will be made publicly available at a date TBD.
Matching Procedures and Assumptions
Matching is based on name similarity, e-mail address domain, physical address, and shared lawyers as representatives (i.e., if the lawyer "Jane Doremi" is determined to be the same entity across multiple cases, then we will cluster and disambiguate the listed firm name so long as it is sufficiently similar). Sometimes a firm's name will change as new lawyers are made partners or existing partners retire; we do not attempt to disambiguate these firm-level changes as the same law firm, since it is impossible to distinguish the difference between the same firm changing its name and a new firm being created from the merger of multiple firms or the dissolution of a large firm based on its name alone.
External Datasets Used
Parties
There is a wide variety of types of entities that can serve as parties to a legal case - ranging from an individual to organizations to the government itself. In an effort to reduce the complexity of the disambiguation problem (given the lack of additional information available for parties), we first attempt to classify the entity name into one of the following categories:
- Corporation
- Prison
- Government
- Person
- Other (i.e., physical or digital objects)
After a party is classified into one of the categories, it is only considered as a potential name for disambiguation within that category - the disambiguation pipelines for the entity categories are mutually exclusive.
The disambiguation pipeline code and classifier will be made publicly available at a date TBD.
Matching Procedures and Assumptions
The major assumptions reside in the classification algorithm to categorize an entity. No attempts are made to disambiguate the Person and Other categories given the potential for two distinct entities to share the same name but not be the same individual or concept.